
Vi sparker i gang høstens fotballsesong med en ny gjesteblogger. Aleksander Eilertsen er statsviter, jobber i skatteetaten og er glad i statistikk og fotballag i røde drakter. Vi har bedt ham om å bruke disse egenskapene til å prøve å sette ny Direktoratsrekord i fotballnerding:
I dette blogginnlegget ser jeg på om statistisk modellering av fotballkamper kan ha noe for seg, og hvordan det i så fall kan hjelpe deg fylle ut tippekupongen. Konkret prøver jeg å spå utfallet av helgens kommende runde i Premier League.
Selv med detaljert ekspertkunnskap kan det være vanskelig å spå utfallet av fotballkamper. Få hadde trodd at nyopprykkede Brann skulle inneha tredjeplassen i årets Tippeliga etter over halvspilt sesong. Ende færre, om noen, hadde regnet med fjorårets Leicester-sensasjon. Og Island viste i sommer at et lite lag kan slå et stort.
Man kan derfor lure på om statistisk modellering egentlig har noe for seg. Uansett hvor god en slik modell er, skal det mye til før den gjør det bedre enn en kunnskapsrik fotballnerd. Men det er likevel verdt å gjøre et forsøk!
Modellen jeg skal vise ser ut til å tippe riktig i 4 av 10 tilfeller. Det er riktig nok litt bedre enn et tilfeldig gjett (som ville vært rundt 3 av 10), men det er ikke akkurat konge. Forhåpentligvis kan den likevel fungere som en god illustrasjon på hvordan statistiske fotballprediksjoner kan gjennomføres. For dem som ønsker å lære mer finnes det en glimrende Wikipedia-side om statistiske fotballprediksjoner.
En velkjent måte å predikere resultatet i fotballkamper på er å modellere antall scorede mål som en Poisson-fordeling (se for eksempel Dixon og Coles (1997) sin klassiske artikkel). At scoringene i Premier League følger en slik fordeling kan illustreres med figurene under.
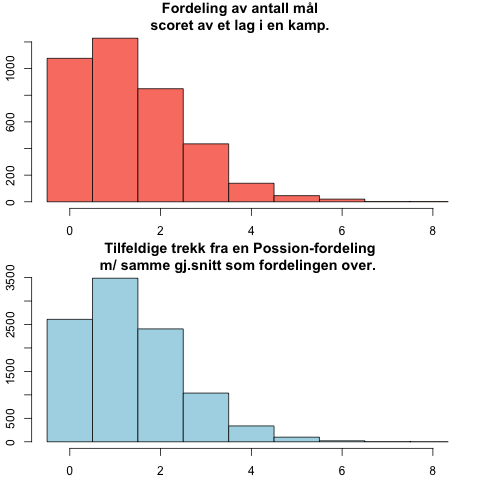
Den øverste figuren viser fordelingen av antall mål et lag scorer i en PL-kamp. Den nederste viser en tilfeldig Poisson-fordeling. Som vi kan se er de to fordelingene nesten helt like, og viser hvorfor Poisson-fordelingen er et populært valg for fotballprediksjoner.
Poisson-fordelingen er ikke helt uten problemer, men den er attraktiv fordi den er enkel å bruke. Jeg kommer derfor til å bruke denne fremgangsmåten her. Noen forslag til forbedringer tas opp til slutt.
Modellen jeg tar i bruk er en bayesiansk hierarkisk poisson-modell. Den er i stor grad kopiert fra Rasmus Bååths (2015) sine La Liga-prediksjoner (all ære for utviklingen av modellen bør gå til ham). Meningen her er ikke å finne den beste modellen for å spå fotballkamper, men å se hvor langt vi kan komme med en relativt enkel modell og hvordan denne gjør det på et nytt datasett.
Den enkleste måten å modellere resultatene i en fotballkamp på er å tenke seg at antall mål hjemmelaget og bortelaget scorer avhenger av deres latente ferdighetsnivå. Differansen mellom ferdighetsnivået til lag i og lag j utgjør det forventede utfallet av kampen.
Goals ~ Possion(λ)
log(λ)=baseline + skilli – skillj
Mange lag er også bedre på hjemmebane enn bortebane, så ferdighetsnivå vil kunne variere med om man er hjemme- eller bortelag. Hvis vi tar høyde for dette blir det forventede antall scorede mål for hjemmelag i og bortelag j dermed:
HomeGoalsi,j ~ Possion(λhome,i,j)
AwayGoals_i,j ~ Possion(λaway,i,j)
log(λhome,i,j)= baselinehome + skilli – skillj
log(λaway,i,j )= baselineaway + skillj – skilli
I tillegg er det trolig at et lags ferdighetsnivå varierer fra år til år, jf. for eksempel Chelseas kollaps og Leicester suksess i fjor. Likevel burde ikke ferdighetsnivået i årets sesong være helt ulikt ferdighetsnivået i fjorårets sesong (selv med ny manager og nye stjerner er ofte hovedtyngden av stallen den samme). Ferdighetsnivået til et lag i sesong t+1 antas derfor å være en normalfordelt funksjon av ferdighetsnivået i sesong t.
Skillt+1 ~ Normal(Skillt,σ2season)
Utgangspunktet for modellen er de 10 siste Premier League-sesongene (2006/07 – 2015/16). Modellen er laget i statistikkprogrammet R sammen det bayesianske analyseverktøyet JAGS. Kampresultatene fra PL som tas i bruk finnes åpent tilgjengelig her. Script for analysen er tilgjengelig på forespørsel.
Så over til det sentrale spørsmålet; klarer modellen å spå utfallet av fotballkamper? Tja. På de historiske dataene som er med i modellen (in-sample) predikerer den 55 % riktig. Det er ikke så verst med tanke på at helt tilfeldige gjett ville gitt oss en prediksjonsrate på 33 % (1 / 3 = 0.33).
Å få en modell til å predikere riktig på dataene du har foran deg er imidlertid ikke spesielt imponerende. Det sentrale vil jo være om den kan forutsi ting fremover i tid. Jeg testet en tilsvarende modell med data fra 2005/06 – 2014/15 for å predikere utfallet av fjorårets sesong (out-of-sample). Da predikerte den 44 % riktig. Det er kanskje ikke noe å hoppe i taket for, men fortsatt bedre enn et ”random guess”.
Hvordan modellen vil gjøre det for årets sesong er ikke godt å si enda. Prediksjonene for 1. runde er vist i tabellen under, slik at du kan dømme selv. Vi ser at det er to ulike mål vi kan legge til grunn; gjennomsnitt (mean) eller typetall (mode). Førstnevnte er et uttrykk for hvor mange mål vi i gjennomsnitt forventer at det scores av hjemme- og bortelaget i en kamp. Sistnevnte er et utrykk for det mest sannsynlige scorede antall mål.
De to fremgangsmåtene gir også ulike resultater. Legger vi gjennomsnittet til grunn predikerte modellen seier til Leicester over Hull (1,6 mål > 1,0 mål), mens legger vi typetallet til grunn predikerte den uavgjort (1 = 1). (Og jada, begge deler var feil. Nyopprykkede Hull slo fjorårets seriemester 2-1…).
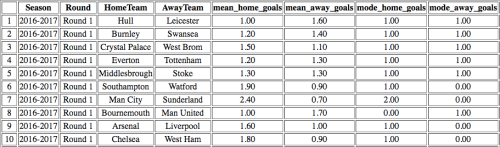
Et problem med å bruke gjennomsnittlige antall scorede mål er at modellen da ikke predikerer uavgjort-resultater i det hele tatt. Et problem med å bruke typetall er at vi da predikerer for få antall borteseire og langt flere uavgjort en det finnes i virkeligheten. I snitt ender de to ulike fremgangsmåtene med å predikere relativt likt out-of-sample (henholdsvis 44,3 % og 43,7 %).
Summerer vi opp prediksjonene i 1. runde og sammenligner dem med de faktiske resultatene ser vi at modellen tippet riktig i 3 av 10 tilfeller hvis vi legger gjennomsnittet til grunn, og 4 av 10 tilfeller hvis vi legger typetallet til grunn.
Oppsummert prediksjonskraft
| In-sample | Out-of-sample | 1. runde 2016/17 | |
| Gjennomsnitt | 55 % | 44,3 % | 3 av 10 |
| Typetall | 49 % | 43,7 % | 4 av 10 |
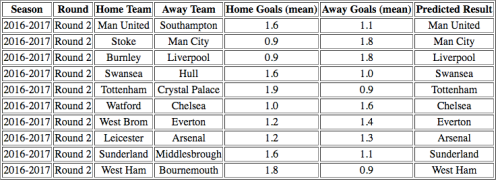
Så til den kommende helgens 2. runde. Modellens prediksjoner er vist i de to tabellene under. Den første tabellen viser prediksjonene hvor gjennomsnittet er lagt til grunn. Som vi ser er ingen av resultatene her uavgjort. Manchester United ser likevel ut til å ha en større fordel mot Southampton (1,6 snittmål mot 1,1) enn den Arsenal har over Leicester (1,3 snittmål vs 1,2). Her er lagene mer eller mindre jevnspilt og uavgjort eller hjemmeseier nesten like sannsynlig som borteseier.
Den andre tabellen viser prediksjonene hvor typetallet er lagt til grunn. Vi ser at den her predikerer 5 av 10 kamper som uavgjort, noe som kanskje er litt i meste laget (i snitt ender ca. ¼ av kamper som uavgjort).
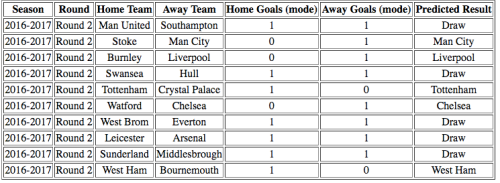
For kampene hvor de to fremgangsmåtene gir samme resultat har jeg større tro på at modellen er inne på noe. Jeg føler meg derfor relativt trygg på at:
- Man City, Liverpool, Tottenham, Chelsea og West Ham stikker av med seieren i sine kamper.
- Man United, Swansea og Sunderland har en fordel i sine kamper (modellen forventer at alle tre i snitt vil score et halvt mål mer enn motstanderen).
- Kampene mellom West Brom – Everton og Leicester – Arsenal er mer åpne. For å holde meg til modellens prediksjoner tipper jeg disse ender i enten uavgjort eller med seier til Arsenal og Everton.
Avslutningsvis kan det jo være greit å vite om man bør tippe på noen av disse kampene. Jeg har derfor regnet ut oddsen til de ulike kampresultatene. Hvis for eksempel Betsson gir oss bedre odds enn disse er det en indikasjon på at vi kanskje kan tjene noen kroner.
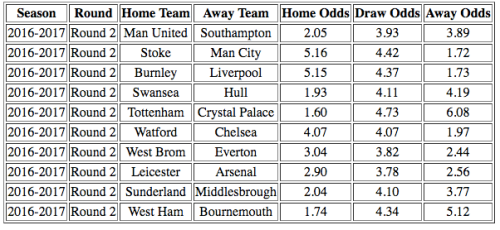
Ser vi for eksempel på kampen mellom Manchester United og Southampton gir Betsson oss odds på
| Hjemme | Uavgjort | Borte |
| 1,46 | 4,50 | 8,80 |
Sammenligner vi dette med den forventede utbetalingen fra modellen ser vi at Betsson gir oss bedre utbetaling for både uavgjort og, ikke minst, borteseier. Er du villig til å ta en sjans ligger det mye penger å hente her. Southampton-seier på Old Trafford kan likevel synes risikabelt.
Et tryggere, men mindre lønnsomt, veddemål er å putte pengene på West Ham-seier hjemme mot Bournemouth. Her anslår modellen en forventet utbetaling 1,74, mens betsson gir deg en noe bedre odds på 1,94.
Helt til slutt. Dette er en relativt enkelt modell, og den har et stort forbedringspotensial. Noen forslag til forbedringer er:
- Trolig vil modellen gjøre det bedre ved å predikere på kampresultater i samme sesong som den vi er inne i. Foreløpig later modellen som vi fortsatt er i 2015/16-sesongen. Etter hvert som årets sesong går sin gang og flere kampresultater kommer inn vil modellen kunne brukes til gi et mer realistisk bilde av 2016/17-sesongen.
- Modellen antar at hjemme- og bortemål er uavhengige av hverandre. Det er ikke nødvendigvis en god forutsetning. En scoring fra et bortelag vil for eksempel kunne tvinge frem et mer aggressivt hjemmelag.
- Modellen veier i dag alle kampresultater like mye. En bedre fremgangsmåte kan være å vekte nyere kampresultater mer enn gamle.
- Poisson-fordelingen er notorisk dårlig til å predikere uavgjort. En annen fremgangsmåte er å modellere scorede mål som en ordinal variabel slik denne bloggposten gjør. Det finnes også en del fordelinger som ligner på Poisson-fordelingen som kanskje kan gjøre det bedre.
- Det er mange faktorer som påvirker resultatet av en fotballkamp, og det er åpenbart at det er potensiale for å inkludere flere variabler i modellen. Forskerne Niek Tax og Yme Jostrua (2015) inkluderer for eksempel; ”winning-streaks”, antall dager siden forrige kamp, om top-scoreren på laget er skadet / i karantene, om laget spilte i en lavere liga året før, antall dager med nåværende manager og mangerbytte den siste måneden.

Heisann!
Liker det jeg leser på bloggen her. Kunne dere vært interessert i et samarbeid med oss i FlashScore? Ta i så fall kontakt med meg på support@flashscore.nu, så kan vi ta det derfra 🙂
Beste hilsen,
Sveinung Karlsen
FlashScore.nu